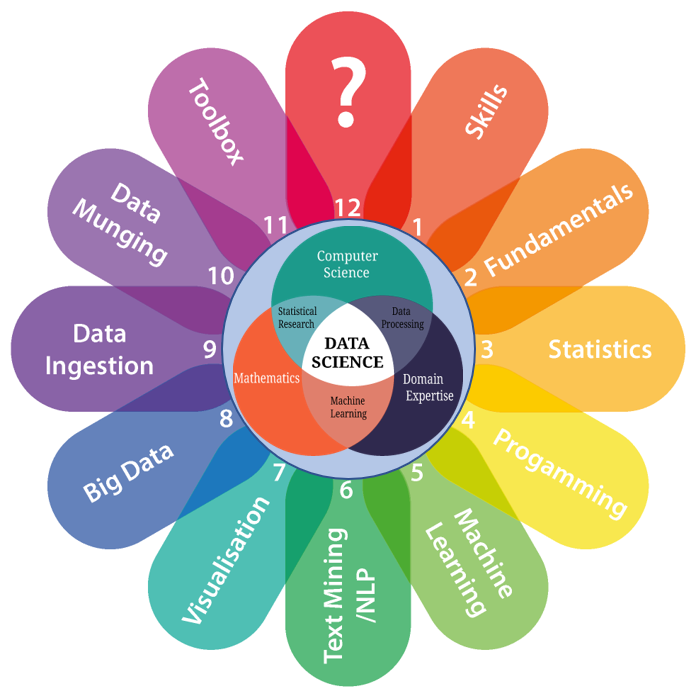
Data Science Learning Path for 2019
As a quick data point, today, on 353rd day of year 2018, I have come across the question from someone “I want to become a ‘Data Scientist, can you help me with a plan?” 48th time so far. If Google search trends tell a story, the frequency of this question coming from within the close and extended working groups also means that ‘Becoming a Data Scientist’ excites a lot of IT practitioners.
Here is my attempt to answer the question for the new entrants and those who are willing to cross/up-skill themselves and eventually become data scientists.
1. Understand the difference between Dreams and Goals:

This is a great quote from all time great Usain Bolt about Dreams and Goals. If you dream to be a data scientist, as a first step, you need to quickly translate that Dream into a SMART goal and remember that the goals do not come without a price. The price is time, effort, sacrifice and sweat. At this point, do not set the goal to have a title as ‘Data Scientist’. Instead, set a learning goal which has measurable milestones and smaller set of intermediate goals.
2. Make a habit of making habits !!
You now have a goal set for your self and also broken it down into smaller intermediate goals, let us make some good habits to stay focused on the learning path.
- Consistency – You need consistent effort and daily commitment of time to stay on the learning path. So many times I come across learners who lose track and cannot be consistent with learning. There are reasons and other priorities which take precedence and create deviation in the plan. Sometimes, the deviation is so much that the learning path is entirely forgotten.
- Focus – You need a focused state of mind to learn the core concepts by reading, practicing, understanding, articulating and discussing. Make a habit of dealing with one thing at a time and consider mindfulness techniques to achieve sharp focus. This may sound a bit off the track for some but it is proven to be a great tool to improve your learning capability.
- Sleep – You need a well rested brain and body to stay consistent and focused on your goal to become a Data Scientist. Research shows that there is correlation between sleep quality and learning ability. Needless to say that for a good quality of sleep and focus, we need to make a habit of optimizing the use of electronic gadgets (specifically Smart Phones).
3. Get Started !!
At this point, you have set the SMART goal and nurtured some habits, let’s get started on the learning path !!
Develop Love for Data !! (Jan 2019)
Before you get to the ‘Science’ part of becoming a Data Scientist, you need to be in love with data. You should be able to see everything in terms of data points and try to take a data driven approach for decision making. The most fundamental way to interact with data is through SQL. SQL mastery is a fundamental characteristic of a Data Scientist and it is the most important and lethal tool in your arsenal. At this point, learn to deal with data in all sizes Small Data / Big Data / Structured Data / Un-Structured Data. In the paradigm of Big Data and it’s management with distributed computing frameworks, remember to have a quick crash course on NoSQL databases.
In God we trust, all others must bring data – Edwards Deming
Master the art of story-telling with data (Feb 2019)
At this point, you are in love with data. Now, you need to be able to tell stories with data. It turns out that story-telling with data is an art more than science. However, you need this artistic skill to excel as a Data Scientist. As an exercise at the end of this month, get access to a public data-set and create a beautifully visualized story.
Understand basics of Mathematics and Statistics (March 2019)
Some of us had a difficult time in understanding the real need for matrix algebra during our school days. It will be an eye opener once you understand the importance of matrix algebra in the context of machine learning algorithms. At this stage in your journey to become a Data Scientist, take my word and get some of your basic mathematics skills back !! Starting with Linear Algebra, explore and practice some examples with Logarithmic, exponential and polynomial functions. Learn basic geometry, complex numbers, series, graphs plotting and most importantly probability theory. A word of caution: do not get disappointed and get too deep into learning these skills and lose the sight at this point. This month may prove to be a road bump in your journey ! Take the diversion and move along.

Learn Python !! (April 2019)
Stay away from all the discussions around R Vs Python and learn and master Python programming.

This is the most handy tool in your hands. Believe me, it is one of the easiest and most powerful language to learn and has a wide range of applicability and use. There is a lot of online material and tutorials available. In any case, you need to be a Python Pro !!
Learn the basic algorithms (the hard way) !! (May 2019)
This is where the rubber meets the road ! First of all get some terminologies right. You need to understand following algorithms one by one. Remember to not use readily available Python libraries for these algorithms. Understand the mathematics, hypothesis and concept well enough for you to code it with core Python syntax.
A word of caution:Most of the budding Data Scientists end their journey at Logistic Regression. If you have move to KNN and Naive Bayes you are a minority !!
Learn and practice some more algorithms (June 2019)
At this point, you are comfortable with coding basic algorithms with Python. Now explore some more algorithms which are commonly used in many situations. Use some of the readily available libraries to implement these with Python. Experiment with various data sets and hyper tuning parameters.
Get used to Jupyter Notebook (Practice Hard) !! (July 2019)
Congratulations !! You are half way through to your Goal. It’s time to celebrate your journey so far. Relax yourself with Jupyter Notebook :). This is by far one of the most handy tools in a Data Scientist’s kitty. It is a unified and easy to use environment for you to try out your code, document it, visualize the results and try variety of experiments. It is a great tool for collaborating with like minded people in your network. In this month, get your hands-on Jupyter Notebooks, try a large variety of data sets, algorithms and visualizations of your data. Create some compelling stories based on the insights you gather from data.
Get your data ready for real action with Pandas (Aug 2019)
At this time of the year, you are now comfortable with Python, commonly used algorithms and storytelling with data. It’s now time to get serious with some real data sets. Pandas aims to be the fundamental high-level building block for doing practical, real world data analysis in Python. Additionally, it has the broader goal of becoming the most powerful and flexible open source data analysis / manipulation tool available in any language. Pandas is suitable for most of the data types we encounter in real life scenarios.
- Tabular data with heterogeneously-typed columns, as in an SQL table or Excel spreadsheet
- Ordered and un-ordered (not necessarily fixed-frequency) time series data.
- Arbitrary matrix data (homogeneously typed or heterogeneous) with row and column labels.
- Any other form of observational / statistical data sets. The data actually need not be labeled at all to be placed into a pandas data structure.
As you get comfortable with Pandas, your data intuition starts getting better with every encounter with data. Yes, intuition plays a role in data science !!
Try various libraries and algorithms and revise concepts (Sept 2019)
In this month, you need to explore more and more python libraries, study and experiment with more algorithms. This is a month for practice and practicing more !! Find answers to following questions yourself and understand the core concepts well enough for you to explain and articulate to others:
- What is over-fitting and under-fitting? What are the techniques used for prevention?
- What are eigenvectors and eigenvalues?
- What is the best treatment for outlier values?
- Explain the terms ‘Precision’ and ‘Recall’. How are they related to the ROC curve?
- What is the trad-off between bias and variance?
- What is gradient descent?
- What is curse of dimensionality and how do you overcome it?
- What is PCA?
Learn about Neural Networks and of course Deep Neural Networks !! (Oct 2019)
Neural Networks and Deep Neural Networks are the Holy Grail of Data Science. Believe me, there is nothing similar to a human brain and how the artificial neural networks work !! However, the artificial neural networks (ANNs) are extremely popular and widely used due to their accuracy especially in dealing with unstructured data (images, audio, video). While there are libraries to implement ANNs, my recommendation is that you understand the concept thoroughly and perform mathematical weight calculations on paper before experimenting with libraries. Practice backpropagation algorithm using derivatives on a piece of paper. Once you understand the core concepts, try a few libraries and classify images and audio data w
Get serious with Tensorflow (Nov 2019)
In order to solve some real problems with your Data Science skills, you need a robust, reliable, community supported library. Your search ends with TensorFlow™. TensorFlow™ is an open source software library for high performance numerical computation. Its flexible architecture allows easy deployment of computation across a variety of platforms (CPUs, GPUs, TPUs), and from desktops to clusters of servers to mobile and edge devices. Originally developed by researchers and engineers from the Google Brain team within Google’s AI organization, it comes with strong support for machine learning and deep learning and the flexible numerical computation core is used across many other scientific domains. Follow all the tutorials, code samples and practice various problems with TensorFlow™ in the month of Nov.
Finally get your hands on Machine Learning on Cloud !! (Dec 2019)
I know for a fact that the enterprises are moving towards a ‘Cloud First‘ strategy, but do not make a mistake of going ‘Cloud First’ in your journey to become a Data Scientist. All three leading cloud platforms (AWS, Azure, GCP) provide easy and ready to use, server-lessplatform for machine learning. It is like using ready-to-cook food by just adding hot water. If you use this, you will never learn the art of cooking !! However, ML on cloud is a way to go. It is going to fully democratize ML and make it super easy to implement algorithms and deal with data in large volume, velocity and variety in a seamless manner. I will not recommend a sequence in which you explore the platforms. I will leave it to best of your judgement and the dynamics of ‘Advanced Analytics’ on cloud market as of Dec 2019 !!
Wishing you a Happy and Prosperous New Year 2019 !! Keep up the learning Spirit !!